Case Study: Peer-Review Assignment and Knowledge Compilation
A program chair has a database of uncertain facts about a conference –
who bid on what, who is expert in what, which papers are assigned – and
keeps asking probability questions of it: how likely is it that every
paper is competently covered? that this reviewer is conflicted? Each
question is a SQL query whose answer carries a probability, and the
interesting thing is that the same kind of question can be easy or
 -hard depending on its exact shape, the schema’s keys, and the
data – and ProvSQL routes each to a different mechanism.
-hard depending on its exact shape, the schema’s keys, and the
data – and ProvSQL routes each to a different mechanism.
This case study walks that landscape over one reviewing dataset, driven through ProvSQL Studio, organised by where the tractability comes from:
Part A – the query is safe. Some questions are tractable whatever the data, because the query (with the schema’s keys) is safe. Four steps cover the four ways that happens.
Part B – the query is hard. When no query-side route applies the answer is genuinely
-hard, and ProvSQL hands it to a knowledge
compiler.Part C – the data is well-structured. A hard query can still be easy on this data, because ProvSQL compiles along the structure of the data itself.
Tip
Follow along in your browser, no install. Open this case study as a
runnable notebook in the ProvSQL Playground, or open the bare cs7 database and follow the Studio steps as
you read. The steps that call an external compiler (d4, c2d) will
not run in the Playground, which bundles none; the built-in
tree-decomposition compiler and everything else do, so the in-process
comparison is fully reproducible. See the Playground note.
The data
Several relations carry per-tuple probabilities. Three drive the coverage questions:
bid(reviewer, paper)– a reviewer offered to review a paper; the probability is how firm the bid is.expertise(reviewer, topic)– the reviewer’s area of competence.topic_of(paper, topic)– the paper is about a topic.
The instance has 14 reviewers, 4 topics and 7 papers. One modelling
choice matters throughout: expertise has a primary key on
reviewer – each reviewer has exactly one area (the functional
dependency reviewer 
topic). Several reviewers share
each area on purpose (five do databases), so a paper’s coverage is
genuinely entangled: the same topic_of tuple is shared by every
co-expert who bid on the paper. The remaining relations – recommend /
champion, an external-review pool, assignment, and two citation /
collaboration graphs – are introduced where first used.
Setup
This case study assumes a working ProvSQL installation
(see Getting ProvSQL) and a running ProvSQL Studio session
(see ProvSQL Studio). Download
setup.sql and load it into a
fresh database:
createdb peer_review_demo
psql -d peer_review_demo -f setup.sql
The script seeds each tuple’s probability and tags every uncertain relation
in Studio’s schema panel with a prov-tid pill (tuple-independent), or
prov-bid for the block-correlated assignment. The provenance class
is the Boolean / Absorptive / Semiring /
Where toggle (see Per-query toggles): most steps want
Boolean, where ProvSQL’s safe-query rewriter and data compilers
are active; Semiring turns them off and shows the literal
circuit; Absorptive is needed only for the cyclic recursion at
the very end.
Part A: The Query Is Safe
A safe query is one whose exact probability is PTIME in the data – whatever the data looks like [Dalvi and Suciu, 2012]. ProvSQL recognises safety at planning time and answers without any compiler. There are exactly four ways a (self-join-free) query can be safe, and the four steps below are one of each.
Safe by shape
We need a coverage shortlist: which papers have at least one plausibly qualified reviewer – someone who bid on the paper and has some area of expertise?
SELECT p.id, p.title
FROM bid b, expertise e, papers p
WHERE b.reviewer = e.reviewer AND b.paper = p.id
GROUP BY p.id, p.title
ORDER BY p.id
Click into p1’s provsql cell and, in the eval strip, pick
Marginal probability with the independent method. It returns
≈ 0.666 instantly – and Compiled d-D circuit with interpret as d-D,
or Tree decomposition, all agree.
Why it works: the query is hierarchical – the atoms mentioning
topic (just expertise) sit inside those mentioning reviewer
(bid and expertise) – so a paper’s coverage is an OR over
reviewers of independent terms, with no tuple shared. The circuit is
read-once, and independent is exact on read-once circuits. This is
the easiest corner: safe by the query’s shape alone, no key needed.
Safe by a key
Now the question that matters for assignment: is paper p1 competently
covered – did someone bid on it who is expert in one of p1‘s own
topics?
SELECT DISTINCT 1
FROM bid b, expertise e, topic_of t
WHERE b.reviewer = e.reviewer
AND e.topic = t.topic
AND b.paper = 'p1' AND t.paper = 'p1'
Try independent with the toggle on Semiring: it
errors – “Not an independent circuit”. Switch the toggle to
Boolean and try again: it succeeds, ≈ 0.4259, matching
Tree decomposition exactly.
The difference is the key. This query is non-hierarchical – bid
mentions only reviewer, topic_of only topic, expertise
both – so its literal lineage reuses the shared topic_of(p1, t1) tuple
(Alice, Bob and Judy are all database experts who bid on p1) and is
not read-once. But because expertise is keyed on reviewer, each
reviewer has a single topic, so the safe-query rewriter can group the
experts by topic and factor that shared tuple out:

Each leaf now appears once – read-once again, and independent is exact.
The lesson: safety depends on the query and the keys together. Drop the
key (ALTER TABLE expertise DROP CONSTRAINT expertise_pkey) and
independent still returns 0.4259, but the route changes – the query
is now genuinely hard and falls through to Part C’s data compiler. Add it
back before continuing:
ALTER TABLE expertise ADD PRIMARY KEY (reviewer);
Safe by a query-derived order
For this step the fixture adds Olga (r15), a prolific reviewer who
skimmed a 24-paper batch, with two post-review signals: recommend (she
recommended a paper) and champion (she would champion it at the meeting).
Which reviewers have bids that back up both a recommendation and a championing – a sign they engaged deeply?
SELECT r.id, r.name
FROM bid b1, recommend a, bid b2, champion c, reviewers r
WHERE b1.reviewer = a.reviewer AND b1.paper = a.paper
AND b1.reviewer = b2.reviewer
AND b2.reviewer = c.reviewer AND b2.paper = c.paper
AND b1.reviewer = r.id
GROUP BY r.id, r.name
On Olga’s row, try the heavy methods first: tree-decomposition gives up
(“Treewidth greater than 10”), possible-worlds refuses (over 64
inputs), and a real compiler (d4) is cut off by statement_timeout on
the 24-paper instance. Then try inversion-free – or just the default
method – and it returns 0.975314 in milliseconds.
Why the gap: grouping on the reviewer makes the two evidence sides share the
bid(r15, *) tuples, so the lineage is not read-once and every
circuit-level method treats it as hard. But the query is a
consistent-unification self-join with a single root variable, which is the
inversion-free condition [Jha and Suciu, 2011]: it admits a
linear-size OBDD over a variable order read from the query. ProvSQL finds
that order at planning time (the teal IF badge on the root is the
certificate) and builds a deep, chain-like d-DNNF – tractability that is
invisible in the materialised circuit and visible only in the query.
Safe by cancellation (Möbius inversion)
The fourth corner is the subtlest, and it needs its own little world: an
external-review pool, isolated from the main instance, where four area
chairs (c1–c4) each run three independent assessment passes – a
prescreen, a score and a flag – over four embargoed submissions
(e1–e4), with lead_chair marking senior chairs and
urgent_sub the time-critical submissions.
Is the pool in a “well-attended” state? – a union of four overlapping
patterns of who-assessed-what. This is the textbook query  /
/
 (Dalvi & Suciu); its four patterns have no tidy English gloss,
because its tractability is purely structural – which is exactly the
point.
(Dalvi & Suciu); its four patterns have no tidy English gloss,
because its tractability is purely structural – which is exactly the
point.
SELECT 1 FROM lead_chair r, prescreen a1, flag_pass a3, urgent_sub t3
WHERE r.chair = a1.chair AND a3.sub = t3.sub
UNION
SELECT 1 FROM prescreen b1, score_pass b2, flag_pass b3, urgent_sub tb
WHERE b1.chair = b2.chair AND b1.sub = b2.sub AND b3.sub = tb.sub
UNION
SELECT 1 FROM score_pass c2, flag_pass c3, flag_pass c3b, urgent_sub tc
WHERE c2.chair = c3.chair AND c2.sub = c3.sub AND c3b.sub = tc.sub
UNION
SELECT 1 FROM lead_chair d, prescreen d1, prescreen d1b,
score_pass d2, score_pass d2b, flag_pass d3
WHERE d.chair = d1.chair AND d1b.chair = d2.chair AND d1b.sub = d2.sub
AND d2b.chair = d3.chair AND d2b.sub = d3.sub
Try Marginal probability with the toggle on Boolean:
it returns the exact 0.056923 with no method named (the chooser routes
it through the Möbius compiler automatically; once the μ root is rendered you
can also pick the mobius method explicitly). Try any circuit
compiler instead and it blows up: provably has no polynomial
OBDD / FBDD / decision-DNNF [Amarilli et al., 2020].
Why it is nonetheless safe: writing the probability by inclusion-exclusion,
the one -hard term – the conjunction of all four patterns –
gets a zero Möbius coefficient and cancels, leaving only easy terms.
ProvSQL’s Möbius compiler computes exactly that signed combination. Click the
existence row’s provsql cell: the circuit is large – the μ
(Möbius-function) root carries the whole literal lineage as a transparent
child, so Studio shows a Circuit too large card – choose
Render at depth 1 and the root is that single μ gate, each
child edge labelled with its integer coefficient, the hard term among them
cancelled to zero. (The pool is dense on purpose: on sparse data
Part C’s compiler would also handle it and hide the point. Like every Part A
route, the gate keeps the literal lineage, so shapley and sr_formula
still work on it.)
The four routes at a glance
These four steps are the complete set of exact query-side routes – the Dalvi-Suciu dichotomy made operational:
The query is safe because… |
ProvSQL route |
Witness in this Part |
|---|---|---|
its shape is hierarchical |
read-once lineage → |
coverage, all papers |
a key makes it read-once |
safe-query rewrite (FD) |
|
a query-derived order |
inversion-free certificate |
Olga’s bid self-join |
its |
Möbius compiler |
the review pool ( |
All four are PTIME, need no external tool, and assume tuple-independent inputs. When none applies, the query is genuinely hard (Part B) – unless the data rescues it (Part C). See the full tractability table.
Part B: The Query Is Hard
Ask the competent-coverage question of the whole program instead of one paper and every Part A route fails. This Part follows that hard query through knowledge compilation.
The hard query, and what a compiler does with it
Is any paper competently covered?
SELECT DISTINCT 1
FROM bid b, expertise e, topic_of t
WHERE b.reviewer = e.reviewer
AND e.topic = t.topic
AND t.paper = b.paper
Set the toggle to Semiring so no Boolean shortcut fires, and
the provenance is the literal circuit of the cyclic join – Studio draws it,
visibly bushy. Try independent: it errors. Try tree-decomposition
or a compiler: ≈ 0.8818.
Why it is hard: with paper free, reviewer, paper and topic
form a cycle with no nesting – non-hierarchical, not inversion-free, and a
single conjunct so nothing cancels. All of Part A is exhausted, and the
probability is -hard [Dalvi and Suciu, 2012]. The
circuit’s treewidth is 4 (against 1 for a safe query), so a real
compiler (Compiled d-D circuit with d4) turns it into a d-DNNF of
order a thousand nodes – and the number 0.8818.
That compiled circuit is the object the rest of Part B inspects.
Reading the CNF back against the data
Pick Tseytin CNF: the panel shows the DIMACS CNF ProvSQL streams to an
external compiler, with one c input comment per variable. Studio
annotates each with the source tuple it stands for, so a model or weighted
count returned by an outside tool reads back against the reviewing data (the
same mapping is a table through tseytin_cnf_mapping).
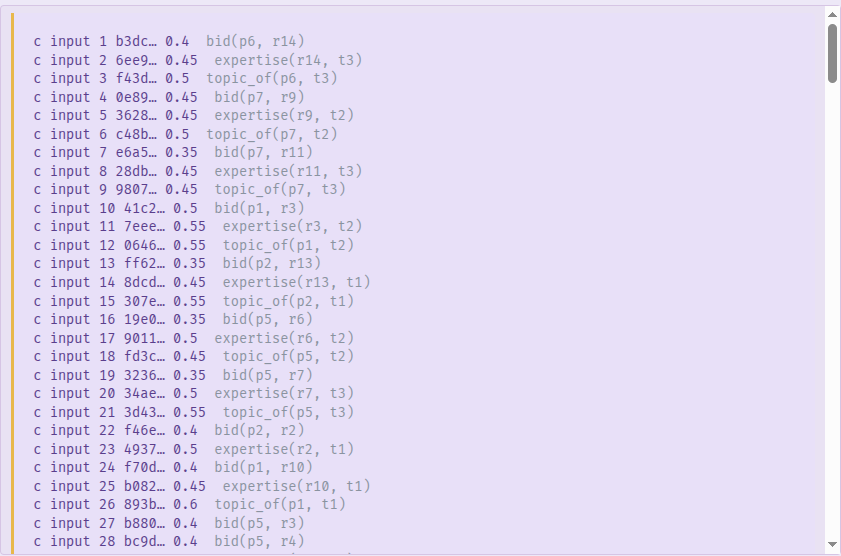
The Tseytin CNF panel for the hard query: each c input line is
annotated with the source tuple the variable stands for
(bid(p6, r14), expertise(r14, t3)…).
Comparing compilers and methods
Pick Probability benchmark: it times every probability method on the hard
circuit, one row each, with the compiled d-DNNF size beside the run time.
Observe the spread: the exact methods that finish (tree-decomposition,
the compilers, the model counters) all agree to full precision;
monte-carlo lands in its confidence band; independent shows its
error; and methods that do not scale – possible-worlds enumeration –
hit the statement_timeout. ddnnf_stats exposes the same sizes
as jsonb for comparing one circuit across compilers.
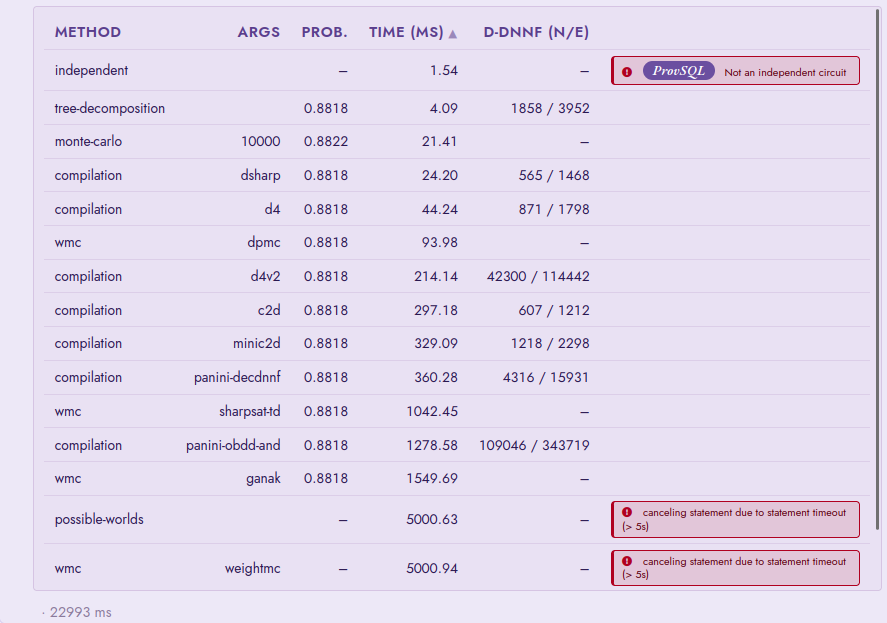
The probability benchmark on the hard circuit: the compilers,
tree-decomposition and the model counters agree on 0.8818;
monte-carlo lands in its band; independent reports the circuit is
not independent; possible-worlds and weightmc time out.
Which compilers appear depends on what is installed; the Tools panel (the
wrench icon) lists the registry and flags each as available / enabled, read
live from provsql.tools (see the external-tool registry).
A shortcut that skips the compiler
Not every hard-looking query reaches a compiler. Which papers have at least two bidding experts?
SELECT p.id, p.title
FROM bid b, expertise e, papers p
WHERE b.reviewer = e.reviewer AND b.paper = p.id
GROUP BY p.id, p.title
HAVING count(*) >= 2
ORDER BY p.id
Compute the probability for p1: it comes back at once, and ProvSQL emits
a NOTICE that the count(*) >= 2 comparison gate was shortcut. The
HAVING threshold over independent contributors is a Poisson-binomial
distribution, which probability_evaluate folds in closed form –
replacing the whole provenance with one Bernoulli gate before any compiler
runs, so even independent answers it.
Part C: The Data Is Well-Structured
Part B’s whole-program coverage is -hard in its shape – yet on
this data it is tractable. When no query-side route applies, ProvSQL still
avoids a compiler if the data is well-structured: it compiles a certified
circuit along a tree decomposition of the data itself, exactly and in linear
time – over independent data, correlated data, and through recursion.
The same hard query, now easy
Set the toggle back to Boolean and re-run Part B’s hard query:
SELECT DISTINCT 1
FROM bid b, expertise e, topic_of t
WHERE b.reviewer = e.reviewer AND e.topic = t.topic AND t.paper = b.paper
Now independent succeeds, the same ≈ 0.8818 – and no compiler
ran. The query is still -hard in shape, but on this data the joint
treewidth (the data graph together with its correlations) is bounded, so
ProvSQL’s joint-width compiler [Amarilli, 2016] recognises the
shape and compiles the provenance along a tree decomposition of the data
into a certified d-D that independent reads in linear time. This is the
route the dropped-key query of Part A fell through to.
Read it per paper – for each paper, how competently is it covered?
SELECT t.paper
FROM bid b, expertise e, topic_of t
WHERE b.reviewer = e.reviewer AND e.topic = t.topic AND t.paper = b.paper
GROUP BY t.paper ORDER BY t.paper
Marginal probability gives each group’s value – p1
0.425869, p4 0.300776 – matching a compiler to full precision,
from the data’s structure with no external tool.
Correlated inputs
So far every relation was tuple-independent. The assignment table lists,
per reviewer, the papers they could be assigned to, made mutually
exclusive by repair_key on reviewer (each reviewer ends up on one
paper). Which papers get an assigned reviewer?
SELECT p.id, p.title
FROM assignment a JOIN papers p ON a.paper = p.id
GROUP BY p.id, p.title
ORDER BY p.id
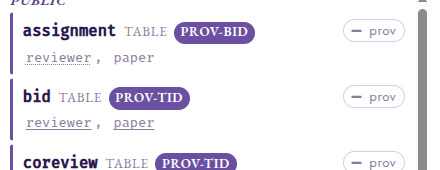
The schema panel distinguishes key kinds: assignment is BID
(repair_key on reviewer, dotted underline); the TID tables carry
solid-underlined primary keys.
Try independent – it agrees with the exact methods (p1 0.875,
p2 0.75). The circuit encodes the mutual exclusion as mulinput
gates sharing a block key, and independent’s evaluator gives mutually
exclusive siblings special treatment (it sums their probabilities within a
block instead of multiplying). So this kind of block correlation, unlike the
cycle of Part B, stays tractable with no compiler at all – because the
query here is safe; only the inputs are correlated.
Hard and correlated
The joint-width route earns its keep where the two regimes meet. Is any
paper covered by its assigned expert reviewer? – Part B’s hard cyclic shape,
now over the correlated assignment table.
SELECT DISTINCT 1
FROM assignment a, expertise e, topic_of t
WHERE a.reviewer = e.reviewer AND e.topic = t.topic AND t.paper = a.paper
Try independent with the toggle on Semiring (the literal
circuit): it rejects it (a reviewer’s candidate papers are mutually
exclusive, so the lineage is neither independent nor read-once), and Part A’s
routes do not apply to the cyclic shape. Switch the toggle back to
Boolean and the joint-width route compiles it anyway: the joint
treewidth – data graph plus the repair_key exclusion blocks – is
bounded, so ProvSQL builds a certified d-D (each block stick-broken into
shared independent events) that independent evaluates to the exact
0.735868. This is the
one cell of the tractability table nothing else
fills: -hard and correlated, exact and linear in the data.
Recursion: reachability and reliability
Note
Recursive queries (WITH RECURSIVE) require PostgreSQL ≥ 15.
ProvSQL tracks provenance through WITH RECURSIVE too: a reachability
answer’s provenance is the disjunction over the paths that reach it. Two more
relations exercise the two regimes: extends(citing, cited) is an
acyclic citation graph, coreview(a, b) a symmetric (hence cyclic)
collaboration graph.
What does paper p6 transitively build on?
WITH RECURSIVE anc(paper) AS (
SELECT 'p6'
UNION
SELECT e.cited FROM extends e JOIN anc a ON e.citing = a.paper
)
SELECT p.id, p.title
FROM anc JOIN papers p ON anc.paper = p.id
WHERE anc.paper <> 'p6' ORDER BY p.id
sr_formula shows each ancestor’s lineage as the conjunction along the
path (p1 is ext(p4,p1) ⊗ ext(p6,p4)) and Marginal
probability gives its value (p1 0.72). Because the graph is acyclic
the lineage is read-once per ancestor, so every semiring evaluation works,
not just probability.
Who is reviewer r1 connected to through co-reviewing? – now a cyclic
walk:
WITH RECURSIVE conn(node) AS (
SELECT 'r1'
UNION
SELECT e.b FROM coreview e JOIN conn c ON e.a = c.node
)
SELECT r.id, r.name
FROM conn JOIN reviewers r ON conn.node = r.id
WHERE conn.node <> 'r1' ORDER BY r.id
With the toggle on Semiring (the default) the fixpoint never
stabilises – “no fixpoint after 1000 rounds (cyclic data?)” – because a
cycle keeps producing new derivations. Switch the toggle to
Absorptive and it
converges:  , so a longer cycle-revisiting path is
absorbed by the shorter one inside it, and the fixpoint is the set of
minimal paths.
, so a longer cycle-revisiting path is
absorbed by the shorter one inside it, and the fixpoint is the set of
minimal paths.
The probability is then two-terminal network reliability – that r1
stays connected when each edge is present independently – which is
-hard in general. Yet Marginal probability reads
r1 reaches r5 with reliability 0.5496 straight off, and even
independent evaluates it. Why: ProvSQL recognises the reachability shape
and, by the provenance form of Courcelle’s theorem
[Amarilli et al., 2015], compiles along a tree decomposition of
the collaboration graph itself into a certified d-D, one per reachable
vertex, linear in the edges when the graph has bounded treewidth (see
Network reliability on bounded-treewidth graphs). That is the case study in miniature: Part B’s
hardness lived in the query and needed a compiler; here – as throughout
Part C – it is dissolved by the structure of the data, with no external
tool. (The 'absorptive' marker on these tokens makes
multiplicity-counting or why-provenance – genuinely infinite on cycles –
refuse rather than return an unjustified value.)
See also
The knowledge-compilation chapter for the full pipeline and every function used here.
The chapter on probabilities for the probability methods and the tractability table that organises this case study.
The Probabilistic Databases synthesis lecture [Suciu et al., 2011] for the theory of safe queries and the dichotomy.